Challenge 4 - Batting average by city
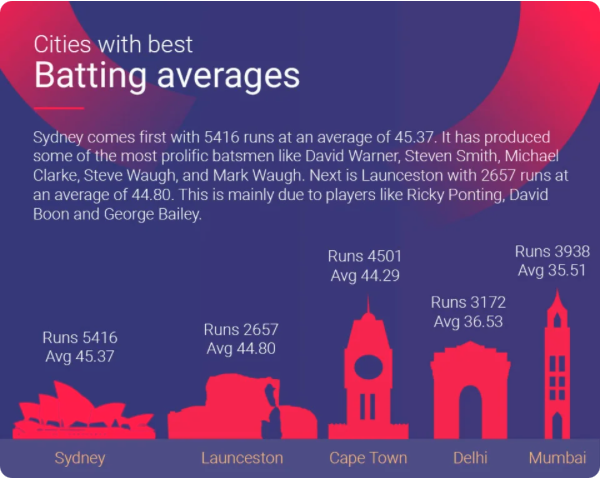
Source: https://www.espncricinfo.com/story/which-top-cricket-city-would-win-the-world-cup-1196522
Found on ESPN Cricinfo - this visualisation really doesn't add anything and is hard to decipher.